In part 2 of this series, I explore an algorithm for combining phonemes.
This is part 2 in the series about searching for a name for this cutie-pie:

Most of the names Maya and I had thought of didn’t have a nice short form or nickname. I figured it’s inevitable that people will shorten a name, both for efficiency and as a term of endearment.
So I decided to try to think of short nicknames that I liked. It got me thinking about short names I’ve heard, like “Cam” (Cameron), “Matt” (Matthew), “Rob” (Robert), “Dick” (Richard), “Serg” (Sergei), and so on.
I remembered that a fellow I used to work with, who was a mathematician and a programmer, had twins and decided to find names for them by enumerating all short names up to four or five letters. I’ve never seen the code he used to do it, but he ended up calling them Zax and Xalen. And those names are so unique that those twins will probably find this article when they Google themselves in 10 years!
I’m a software engineer with a physics background, and I’ve done a bunch of work on exploring algorithmic approaches to open-ended research questions. So naturally my first inclination is to write an algorithm to solve the problem.
But how do you write an algorithm to name a human?!
Well for starters, I wanted to try somehow systematically exploring all short nicknames, like with a maximum of two syllables perhaps.
I first tried coming up with basic combinations of vowel and consonant sounds, spelled out phonetically:
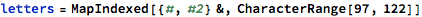
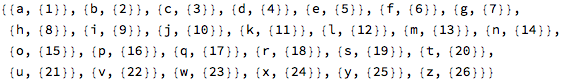
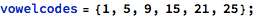

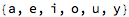

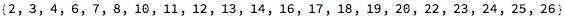

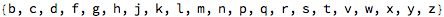

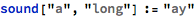

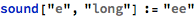
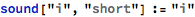
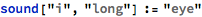

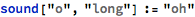



I wrote some code that produced a button that would sound the word out audibly:
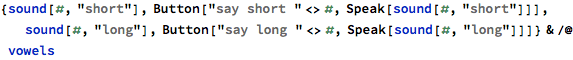

I tried combining random vowel and consonant sounds in particular patterns, like vowel-consonant-vowel-consonant, and wrote a basic interface to thumbs-up names that sounded reasonable:


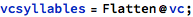
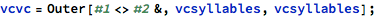

Unfortunately all of these names sounded like sci-fi characters. Since my kid wasn’t going to be a Klingon, this seemed less than ideal.
But this was a good start. I was systematically producing short names, and had the ability to listen to what a name sounded like, and to keep track of names that had potential.
I realized that the idea of combining basic sounds to produce a word is a familiar concept from linguistics. The basic sounds are called “phonemes”:


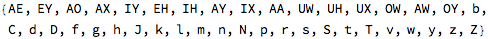
Here are (most of) the phonemes, in ARPA notation, with an example word for each:

Using phonemes, I could systematically explore the basic sounds that are universal to all human languages. So I started by exploring names containing two phonemes, with a consonant sound followed by a vowel sound (detailed code on my blog here). Here’s the “b” sound followed by a vowel sound:


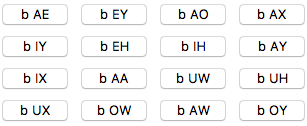

I tried combining random phonemes in the pattern consonant + vowel + consonant:


With 24 consonant phonemes and 16 vowel phonemes, how many possible names are there of the form consonant + vowel + consonant?
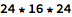
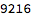
About 10k combinations.
It seems conceivable that I could systematically listen to 10k names, but at 5 sec/name it would take 12 hours straight to listen to them all.
So to start with, I generated random examples to listen to:

I then tried the pattern vowel + consonant + vowel:

None of these names sounded reasonable to me. They just didn’t sound like English at all.
I realized the names didn’t sound familiar to me because although I was using simple basic sounds, I was combining them in unfamiliar patterns. In particular, English words tend to have phonemes occurring next to each other frequently, like “t” and “s” in “beets” and “cats”, or “n” and “oo” in “noon” and “new”.
Luckily I had a dataset containing the English dictionary (from the WordData function in Mathematica), where each word was broken down into phonemes:
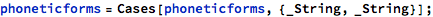


https://paul-jean.github.io/baby-name//2017/02/23/babynames-06-markov-model-name-generator.html
So I could take this data and find how often one phoneme occurs next to another. Here is a sample of the 173k adjacent phoneme pairs from the dictionary data, with their counts:


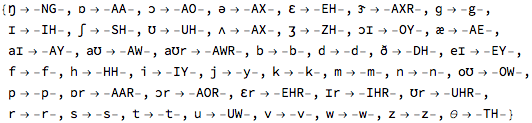





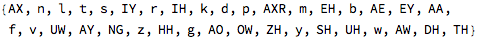
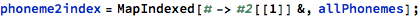
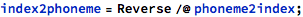


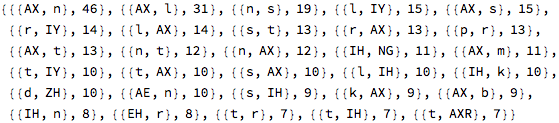
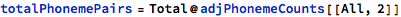
Here I’m using the ARPA notation for phonemes . I built a conversion table from the IPA notation used in WordData:
Using this data I could derive a transition matrix from one phoneme to another:


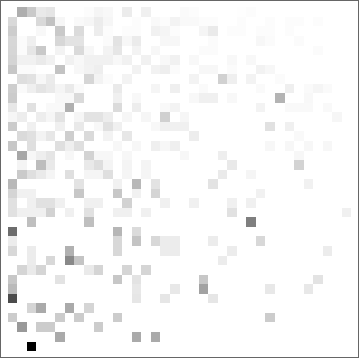
There were 37 phonemes in the English dictionary data. Here they are numbered from 1 to 37:
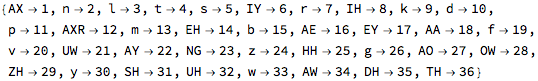
This numbering is used to define a position in the transition matrix. So the element at position {10, 20} is the relative frequency that phoneme 10 (“IY”) occurs next to phoneme 20 (“f”), as in the word “leaf”.
In other words, element {i, j} in the transition matrix is the probability that phoneme i is followed by phoneme j in an English word.
Using this transition matrix, I could build up an entirely new word by starting with a particular phoneme like “t” and then choosing the next phoneme in the word using the “t” row in the transition matrix. The “t” row tells me how often “t” is followed by each other phoneme, like “t” -> “s” or “t” -> “ee”. I could make a random choice for the next phoneme in the word, weighted by the probabilities in the “t” row.
When you build up a sequence like this, and all you take into account is the probability of neighboring elements, it’s called a Markov chain. So what I had done was create a Markov chain over phonemes, based on the adjacent phonemes in English words.
I could use my model to generate completely new words:

For example, generating a random word with 3 phonemes:
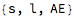
And generating 30 random words with 3 phonemes:

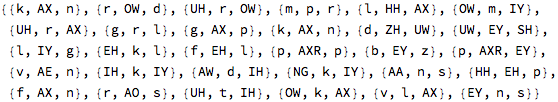
Just looking at phonemes isn’t super insightful for me, so I built a button that would speak a word based on the sequence of phonemes in the word:

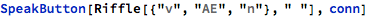

In addition, each time I clicked the button to hear how the word sounds, it increments a counter in a database for that particular word. So I could keep track how many times I listened to a word, as a rough gauge of how “interesting” that word was to me.
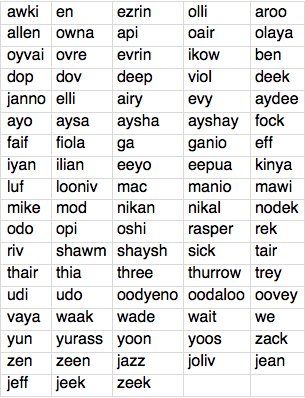
So using my word generator, I started making grids of words and clicking on them to see how they sounded:


So far all of these words were just based on the adjacent phonemes in the English dictionary. But as I clicked on words to listen to them, I was creating a database of words and how interesting I found them as potential baby names:
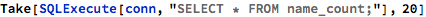

If I listened to a word just once or twice, I probably didn’t find it very interesting. But if I clicked on it three or more times, it was likely that there was something about that word that might be worth considering for a name. So I took the words that I clicked on three or more times:
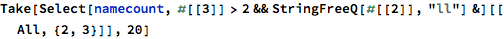

… and extracted the adjacent phoneme counts from them, just like I did for the English dictionary words:


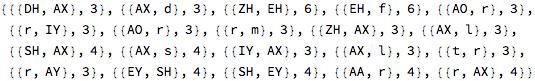
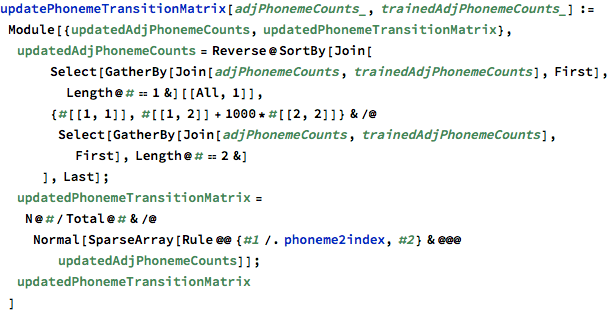
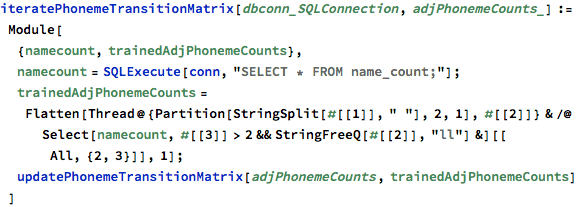
I then used these favorite adjacent phonemes to update the transition matrix, taking these additional preferred phoneme transitions into account with a high weighting factor:
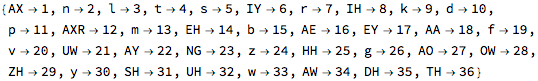
I could then re-generate a new set of words with these updated transition probabilities that included my word preferences:

I could repeat this feedback process to steadily skew the generated words towards the kinds of words I found interesting. In machine learning this is called training. I was training my phoneme Markov chain, by reinforcing adjacent phonemes in the words that I like the sound of.
So gradually I built up a new phoneme transition matrix that was heavily weighted towards my word preferences:
At this point the names were getting slightly more reasonable-sounding as potential names:
https://paul-jean.github.io/baby-name//2017/02/23/babynames-07-transition-matrix-iterate.html
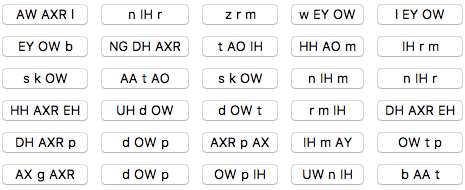
The names I listened to the most and therefore seemed to have the most interest in were:
I had built a rudimentary machine learning model for generating new names from phonemes:
-
build a phoneme adjacency/transition matrix from dictionary words
-
generate random words from a Markov chain using the transition matrix from 1
-
record how many times I listen to the spoken form of each word, as a measure of interest in the sound of that word
-
build a new phoneme transition matrix from just the words I listened to more than twice
-
combine the transition matrix from 1 with the transition matrix from 5 to form an updated transition matrix, heavily weighting the transitions from 5
-
go to step 2, generating a new set of random words to listen to …. rinse and repeat
I was training the model in successive stages, based on combinations of phonemes that sounded good to my ear.
While some of these names are plausible names for a human, they weren’t winning any prizes. And finding each slightly reasonable ones took listening to tens of generated phoneme combos, which was slow, tedious work. So I felt like I needed another approach.
In part 3, I’ll talk about a new approach I tried based on mining a database of names for patterns.